
了解JVM(深入了解Java虚拟机浅读)
1 | 2021-12-1 更新记录 |
Java内存区域
运行时数据区域
- 进程中线程共享:
- 堆
- 方法区
- 进程中线程私有:
- 程序计数器
- 虚拟机栈
- 本地方法栈
程序计数器(一块较小的内存空间)
- java是编译成字节码运行,程序计数器可看作当前线程执行字节码的行号指示器。
- 多线程情况下,程序计数器用于记录当前线程的执行位置,当线程切换回来可知道线程上次运行的位置。
各线程之间程序计数器互不影响,独立存储,这一块内存是线程私有的内存。
虚拟机栈(Java方法)
与程序计数器一样,Java虚拟机栈是线程私有的,用于描述Java方法执行的内存模型,每次方法调用数据都是通过栈传递。
虚拟机栈生命周期与线程一样,当方法被执行时,JVM会同步创建一个栈帧(用于存储局部变量表、操作数栈、动态链接、方法出口等信息),每一个方法执行的过程就相当于栈帧在虚拟机栈中入栈到出栈。
Java内存可大致分为堆内存和栈内存,栈指的是虚拟机栈,或者是虚拟机栈的局部变量表部分。
局部变量表用于存放方法参数和方法内部定义的局部变量。其存放了编译期可知的8种基本数据类型、对象引用(reference类型,并不等于对象本身,可能是一个指向对象起始地址的引用指针,也可能是指向一个代表对象的句柄或其他与此对象相关的位置)、returnAddress类型(指向了一条字节码指令的地址,也就是方法退出时的返回地址,有正常调用退出和异常调用完成退出两种情况,该字节码是为了方法结束时,将结果返回上层调用者)。
本地方法栈(Native方法)
作用与虚拟机栈相似,虚拟机栈为JVM使用的Java方法服务,本地方法栈为JVM使用的Native方法服务。功能和虚拟机栈一致。
堆
JVM内存管理中最大的一块,堆是所有线程共享的内存区域,在虚拟机启动时创建。该区域的唯一目的就是存放对象实例,几乎所有对象实例及数组都在这分配内存,Java堆是垃圾收集器的主要区域,也被称作GC堆。
方法区
与堆一样,方法区是线程共享的内存区域,它用于存储已被JVM加载的类型信息、常量、静态变量、即时编译器编译后的代码等数据。也称作非堆。JDK8前方法区实现为永久代,JDK8后实现为元空间。
JDK7将字符串常量池、静态变量等移至堆,JDK8后移除永久代,被元空间代替。
运行时常量池
运行时常量池是方法区的一部分。
字符串常量池在JDK7后移至堆,属于JVM常量池,包装类常量池准确说时对象池,只是用了常量池技术而已,其属于Java层面。如Integer常量池是一个cache数组存储。
直接内存
直接内存并非是虚拟机运行时数据区的一部分,也不是虚拟机规范中定义的内存区域。
HotSpot
JVM相当于一个虚拟机规范,而HotSpot就是规范的具体实现。以下基于HotSpot。
对象的创建
new,类加载检查
虚拟机遇到一条new指令时,会检查当前指令的参数是否能在常量池中定位到这个类的符号引用,并检查该符号引用的类是否已加载。若没有,则执行相应的类加载过程。
分配内存
在类加载检查后,虚拟机会为新对象分配内存。类加载完成后可确定对象所需的内存大小,此时只需要将确定大小的内存从Java堆中划分出来。Java堆有两种分配方式:
指针碰撞
内存空间规整,即一边是使用过的内存,另一边是空闲内存,指针只需要在中间挪动
空闲列表
内存空间分布不规整,占用内存和空闲内存相交错,JVM需要维护一个列表,记录可用的内存块。
分配的方法是根据其规整情况,也就是垃圾收集器来选择,其回收算法不同,导致内存空间情况不同。
而对于并发情况下的内存分配有两种方法:
- 分配操作同步处理,CAS + 失败重试保证操作原子性
- 本地线程分配缓冲TLAB,每个线程在堆中预先分配内存,在各自内存进行操作
初始化零值
内存分配后,虚拟机将分配的内存空间都初始化为零值(不包括对象头),该操作是为了保证对象的实例字段可不赋初始值就直接使用,程序则会访问该实例字段对应类型的初始值。
设置对象头
初始化零值后,虚拟机会将对象的相关信息存放到对象头中,如哈希码、GC分代年龄、锁相关信息、类的元数据信息等。
执行
<init>()方法,构造函数虚拟机完成了对象创建,但对于程序来说,对象创建才刚开始,此时执行init()方法,初始化对象。new指令后接着执行
<init>()方法。
对象内存布局
对象在内存中布局可分为3快区域:对象头、实例数据、对齐填充。
对象头:包含两部分信息,一部分用于存储对象自身运行时数据,另一部分是类型指针(对象指向其类元数据的指针),虚拟机通过该指针确定对象是某个类的实例。
实例数据:对象真正存储的有效信息。
对齐填充:不是必要的,仅仅起占位作用。由于HotSpot虚拟机要求对象大小必须是8字节的整数倍,通过对齐填充补齐。
对象的访问定位
通过句柄和直接指针两种方式实现访问定位。
句柄访问
Java堆会划分出句柄池的内存,reference存放对象的句柄地址,句柄中包含了对象实例数据和类型数据的具体地址信息。根据想访问的信息,进行间接访问。
优点:reference存储的句柄地址稳定,对象被移动时,只会改变句柄中的指针信息,reference本身不会修改。
直接指针访问(HotSpot)
reference存储的是对象地址,此时Java堆中对象的内存布局需要考虑如何放置访问类型数据的相关信息。如果之访问对象实例信息,则无需间接访问的开销,因为对象内存布局包含了对象的实例信息。
优点:访问速度快,节省了指针定位的时间开销。
java实例数据:堆(对象布局)
java类型数据:方法区
JVM垃圾回收
堆空间分配与垃圾回收
基本结构
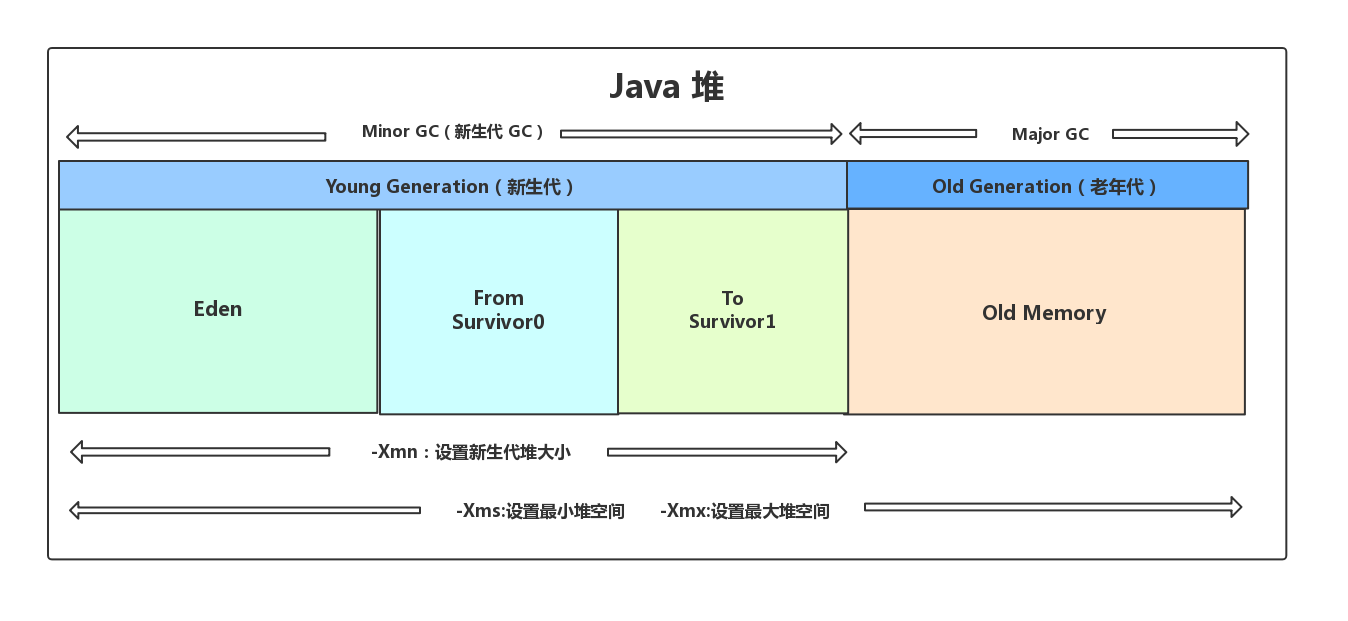
新生代内存:eden、from survivor0(s0)、to survivor1(s1)
老年代内存:old memory
Minor GC:新生代垃圾回收
Major GC:老年代垃圾回收,CMS
Mixed GC:对整个新生代与部分老年代进行垃圾回收,G1
Full GC:清理整个Java堆和方法区的垃圾收集
对象会优先在eden区域分配
大对象直接进入老年代,大对象即大量连续内存空间的Java对象,如长字符串,元素数量庞大的数组
长期存活对象进入老年代,JVM为每个对象定义了一个对象年龄计算器,存储在对象头中,一般对象在eden区诞生,若经过一次Minor GC并被Survivor区容纳,则年龄+1,达到一定值(默认15)则晋升为老年代。
如何判断对象是否可回收
引用计数法
给对象添加引用计数器,每次引用+1,引用失效-1,计数器=0即对象可回收。
但由于对象之间会产生循环引用问题,主流虚拟机并没有使用该算法进行内存管理。
可达性分析算法
通过一系列称为GC Roots的根对象作为起始节点集,所有该节点可达到的对象是存活的,不可达的对象可被回收。
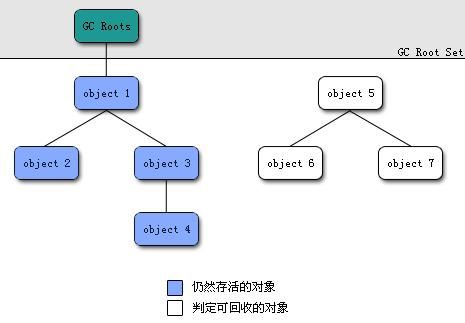
GC Roots的选取一般为以下几种:
- 虚拟机栈中引用的对象,如方法参数、局部变量等
- 本地方法栈中(Native方法)引用的对象
- 方法区中类静态属性引用的对象
- 方法区中常量引用的对象
- 所有被同步锁持有的对象
- JVM内部引用,如基本数据类型对应的Class对象
在可达性算法中,为了完成对象图的遍历,引入了三色标记进行辅助:
- 白色:当前对象尚未被访问,最终仍为白色的对象即不可达的
- 黑色:对象及其引用都被访问过,全部存活,后续不会重复扫描
- 灰色:当前对象被访问过,但其关系上至少有一个引用未被扫描
在可达性扫描中可能会遭遇并发问题,导致黑色对象更改后关系链上多出了白色对象,一般是插入或删除了一些引用导致的,进而引申出两种解决方法 增量更新 和 原始快照(SATB),它们解决办法都是记录更改,后续重新遍历关系进行确认。
四种引用类型
强引用
被强引用关联的对象不会回收。
使用 new 关键字来创建强引用。
软引用
软引用关联对象只有在内存不足时才会被回收。
使用 SoftReference类 来创建软引用。
弱引用
弱引用关联的对象一定会被回收,只能存活到下一次垃圾回收发生之前。
使用 WeakReference类 来创建软引用。
虚引用
一个对象是否有虚引用的存在,不会对其生存时间造成影响,也无法通过虚引用得到对象。
为一个对象设置虚引用的唯一作用,就是该对象被回收时会收到一个系统通知。
使用 PhantomReference类 来创建虚引用。
垃圾回收算法
分代收集
垃圾收集算法可划分为 引用计数式垃圾收集 和 追踪式垃圾收集 两类,也叫做直接、间接垃圾收集,而我们主流JVM使用的算法都是属于追踪式垃圾收集。
而垃圾收集器都是以 分代收集 理论作为基础的,其建立在几个假说之上:
- 弱分代假说:大部分对象都会朝生夕灭,即在新生代就被GC。
- 强分代假说:对象活的越久,经历过更多次的GC,该对象就功能消亡,也就是晋升为老年代。
- 跨代引用假说:跨代引用,即两个相互作用的对象,其更倾向于同生同灭,如新生代对象与老年代对象相互作用,那么新生代在GC时因为引用得以存活,逐渐晋升到老年代,跨代引用消除。
标记–清除(内存分配复杂,老年代)
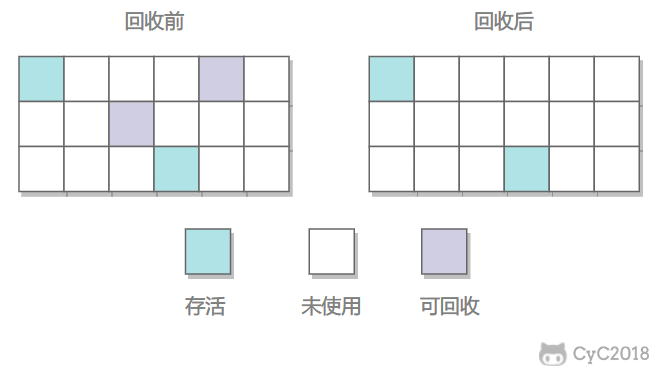
标记所有要回收(不要回收)的对象,标记完成后,统一回收所有标记(未被标记)的对象,该算法是最基础的回收算法,其余算法都是对它的改进。
缺点:
- 标记==清除执行效率不稳定,会随着对象数量增长而降低
- 会导致内存空间碎片化
标记–整理(内存回收复杂,老年代)
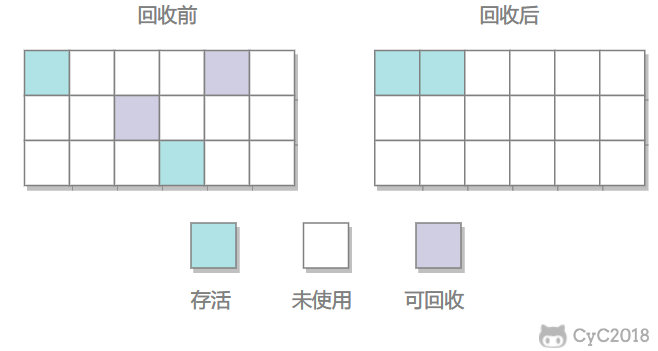
让所有的存活对象向内存空间一端移动,随后清理边界以外的内存。
优点:不会产生内存碎片
缺点:移动大量对象,需要暂停用户应用程序进行,效率低
标记–复制(新生代)
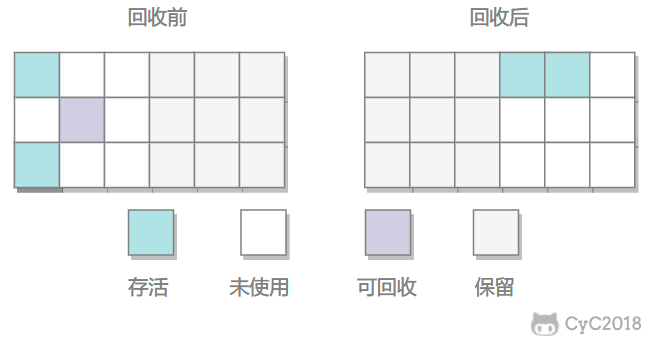
将内存划分为大小相等的两块,每次只使用其中一块,当这一块内存使用完后,先将存活对象全部复制到另一块上,然后再将这一块内存清理。保证有一半的区域充当备用。
后续Andrew Appel进行优化,称作 Appel式回收,将新生代分为一块较大的Eden空间和两块较小的Survivor空间,而每次的内存分配只使用Eden和其中一块Survivor,复制算法会体现在两个Survivor空间上,当Survivor空间没有空闲时,对象将有分配担保机制进入老年代。
HotSpot默认分配Eden和Survivor的比例是8:1:1,也就是说新生代可用空间为总空间的90%,只浪费了10%的空间。
缺点:内存只能使用部分,空间浪费。
垃圾收集器
垃圾收集器
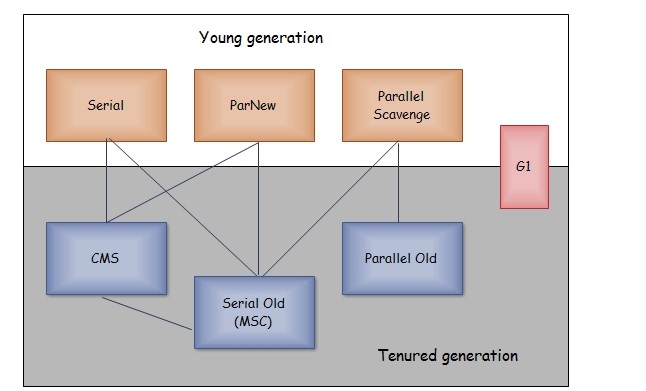
新生代(标记–复制)
Serial收集器(Client,单线程)
单线程收集器,GC时会暂停所有其他工作线程,但相比其他收集器的单线程更加简单高效,且对于内存受限的环境,它是所有收集器里额外内存消耗最小的,没有线程交互的开销。
ParNew收集器(Server,多线程)
Serial的多线程版本,除了支持多线程外和Serial一致,除了Serial外,只有它可以和CMS收集器配合使用。
Parallel Scavenge收集器(吞吐量优先)
多线程收集器,其他收集器在意的是用户线程的停顿时间,而它的关注点是达到一个可控的吞吐量,即高效利用CPU时间。适合用于后台运算且无需太多交互的任务。
老年代(标记–清除、标记–整理)
Serial Old收集器(Client,单线程)
Serial的老年代版本。主要有两大作用:一是JDK1.5以前与 Parallel Scavenge 搭配使用,二是作为CMS收集器发送失败的后备方案。
Parallel Old收集器(多线程,吞吐量)
Parallel Scavenge的老年代版本,注重吞吐量或CPU资源敏感时,可考虑使用Parallel Scavenge + Parallel Old。
CMS收集器(Concurrent Mark Sweep)
CMS的MS即Mark Sweep标记清除算法,此处实现步骤分4步:
- 初始标记:标记GC Roots能直接关联的对象,速度快,需要停顿。
- 并发标记:从GC Roots的直接关联对象遍历整个对象图的过程,在整个回收过程中耗时最长,无需停顿。
- 重新标记:为了修正并发标记期间,因用户程序继续运作,进而导致标记产生变动的部分对象的标记记录,需要停顿。也就是可达性算法并发情况下增量更新解决的问题。
- 并发清除:清理标记阶段判断为已死亡的对象,无需停顿。
优点:并发收集,低停顿。
缺点:
- 吞吐量低,CPU利用率不高。
- 无法处理浮动垃圾,可启用Serial Old进行替代。
- 标记–清除算法会产生空间碎片,使得没有大空间来分配对象,进而导致提前使用Full GC。可以在多次 标记–清除 后执行 标记–整理 避免空间浪费。
G1收集器(server)
G1不在局限于分代,它可以处理新生代和老年代,是特殊的Mixed GC。
G1不在以固定大小和固定数量划分分代空间,而是将连续的Java堆分为多个大小相同的独立区域(Region),每一个Region根据需求扮演新生代(Eden、Survivor)、老年代。
运作过程:
- 初始标记:GC Roots能直接关联的对象·····,需要暂停。
- 并发标记:从GC Roots进行可达性分析,递归整个对象图
- 最终标记:处理 原始快照SATB 问题。短暂暂停。
- 筛选回收:更新Region,对Region回收价值与成本进行排序,然后进行回收。需要暂停。
特点:
- 空间整合:整体基于 标记–整理 实现,局部基于 标记–复制 实现,即运行时不会产生空间碎片。
- 可预测停顿:指明使用者在某长度时间片段内,GC不得超过相应的规定时间。
- 分Region的内存分布
低延迟垃圾收集器
- Shenandoah收集器
- ZGC
二者都是基于Region的内存布局,ZGC更优秀,可在任意内存大小下,都将垃圾收集的停顿时间限制在10ms以内的低延迟。
类加载机制
类加载时机
只有6种主动引用才会触发初始化,其他的引用类型方式都不会触发初始化,称为被动引用。
主动引用
- 遇到
new、getstatic、putstatic、invokestatic这四个字节码指令时,若当前类型没有初始化则触发其初始化。- 使用new实例化对象
- 读取 或 设置 一个类型的静态字段时(被final修饰的静态字段 和 在编译器将结果放入常量池的静态字段 除外)
- 调用一个类型的静态字段时
- 对类型进行反射调用时,该类型没有初始化。
- 当初始化类时,其父类未初始化,则先去初始化该父类;而接口初始化时,不要求其父接口全部初始化,只有用到父接口时才会初始化。
- JVM启动时,优先初始化主类(含main()的类)。
- 使用JDK7加入的动态语句支持,某实例解析结果为REF_getStatic、REF_putStatic、REF_invokeStatic、REF_newInvokeSpecial,这四种类型的方法句柄,且该方法句柄对应类未进行初始化时。
- 当一个接口定义了JDK8新加入的默认方法(default关键字修饰),若该接口的实现类发生了初始化,该接口要在其之前被初始化。
被动引用(举例)
- 通过子类引用父类的静态字段,不会导致子类初始化。对于静态字段,只有直接定义该字段的类才会被初始化,所以当静态字段在父类时,通过子类引用该字段,只会触发父类的初始化。
- 通过数组定义来引用类,不会触发该类的初始化。定义一个类的数组,直接由虚拟机自动生成,继承于Object,创建动作由字节码指令anewarray触发,而该类不会初始化。
- 引用类的常量,(static final)常量在编译阶段会存入调用类的常量池,本质上没有直接引用到定义常量的类,所以不会触发常量所属类的初始化。
类的生命周期
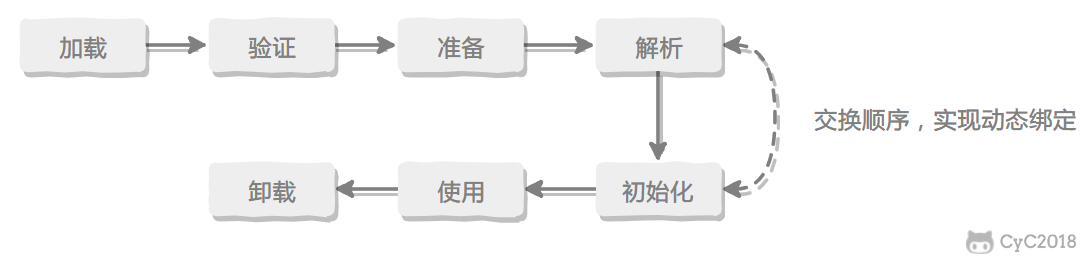
- 加载
- 验证
- 准备
- 解析
- 初始化
- 使用
- 卸载
其中验证、准备、解析,统称为连接阶段。
类加载过程
包括了加载、验证、准备、解析、初始化5个阶段。
加载
在加载阶段,JVM会完成以下三件事:
通过类的全限定名来获取此类的二进制字节流。
将字节流所代表的 静态存储结构 转换成方法区的 运行时存储结构。
在内存中生成一个代表该类的 java.lang.Class对象,作为方法区中该类各种数据的访问入口。
但以上三点要求并不具体,有很大的发挥空间,如没有明确指明从哪里获取、如何获取等。由此引申出了一些技术,如ZIP压缩包读取加载,即JAR、WAR等;网络获取;JSP等。
非数组类型的加载阶段可以用上述多种方式进行,而数组类本身不提供类加载器创建,其元素类型最终还是由类加载器完成加载。
加载阶段与连接阶段的部分动作时交叉进行的。
验证
验证阶段大致可分为四步校验动作:
- 文件格式验证:字节流是否符号Class文件格式规范
- 元数据验证:对字节码描述信息进行语义分析(父类、抽象类、继承、数据类型等相关校验)
- 字节码验证:通过数据流、控制流分析,确定程序语义是否合法,符合逻辑。(对方法体校验)
- 符号引用验证:该阶段实际发生在JVM将符号引用转化为直接引用时,是解析阶段才发生的。(该类是否 缺少 或 被禁止访问 它依赖的资源)
验证阶段对于JVM类加载机制来说,是一个重要但不是必要的阶段,因为该阶段只有通过或不通过的差别,通过验证对后续程序运行无影响,所以当我们的程序被反复使用和验证后,可在生产环境的实施阶段关闭大部分的类验证措施(-Xverify:none),缩短JVM加载的时间。
准备
为类中定义的静态变量分配内存并设置类变量初始值的阶段,这些变量内存理论上应在方法区分配。而逻辑上的方法区有具体的实现,JDK7之前,是永久代实现方法区,变量分配在方法区上;而JDK7后类变量迁移到Java堆中进行分配。
当然准备阶段进行内存分配的仅仅是类变量,不包括实例变量,实例变量是随着对象实例化和对象一起分配到Java堆中。
设置类变量初始值也分情况:
1 | public static int value = 111; |
第一种value在准备阶段设置初值=0,而不是111,因为此时并未执行Java方法,只有value赋值111的对应putstatic指令被编译后,才会被复制,也就是到初始化阶段才会赋值111。
当然也有例外,如果类字段的字段属性表存在ConstantValue属性,准备阶段就会初始成该值。被final修饰的类变量,在编译时会生成ConstantValue属性,在准备阶段JVM根据该属性赋值value=111。
解析
JVM将常量池符号引用替换成直接引用的过程。
符号引用:以一组符号描述引用的目标,可以是任何形式的字面量。与JVM内存布局无关,各自JVM实现内存布局不相同,但它们接受符号引用必须一致。(字符串)
符号引用通常指代全限定名、包名、字段和方法的名称与描述符。
直接引用:可以是直接指向目标的指针、相对偏移量或一个间接定位目标的句柄。与JVM内存布局直接相关,有了直接引用,该引用的目标必定存在于JVM内存中。(内存地址)
也就是说将包名、全限定名这种字符串表示量转换成相应的内存地址。
初始化
初始化阶段才是真正开始执行类中定义的Java代码,进行准备阶段时,变量已经设置了初值,到了初始化阶段,会根据程序编码去初始化类变量和资源。初始化阶段就是执行类构造器 <clinit>() 方法的过程。
<clinit>() 方法是 类变量 + 静态语句块。
类加载器
类加载阶段中 “通过类全限定名获取该类的二进制字节流”,JVM的设计团队希望这个动作可以放到JVM外部去实现,也就是让程序自行决定如何去获取所需要的类。类加载器只用于实现类的加载动作,可确定类在JVM中的唯一性,且每一个类加载器有独立的类名称空间。
可以比较两个类是否 “相等”,只有两个类是同一个类加载器加载的前提下才相等。即使两个类来自同一个Class文件,被同一个JVM加载,只要它们的类加载器不同,这两个类就不相等。
对于JVM来说,只存在两种类加载器,启动类加载器(C++实现,是JVM的一部分) 和 其他所有的类加载器(这些是由Java实现的,独立存在于JVM外部)。
Java一致保持三层类加载器、双亲委派的类加载结构。
三层类加载器 + 双亲委派模型
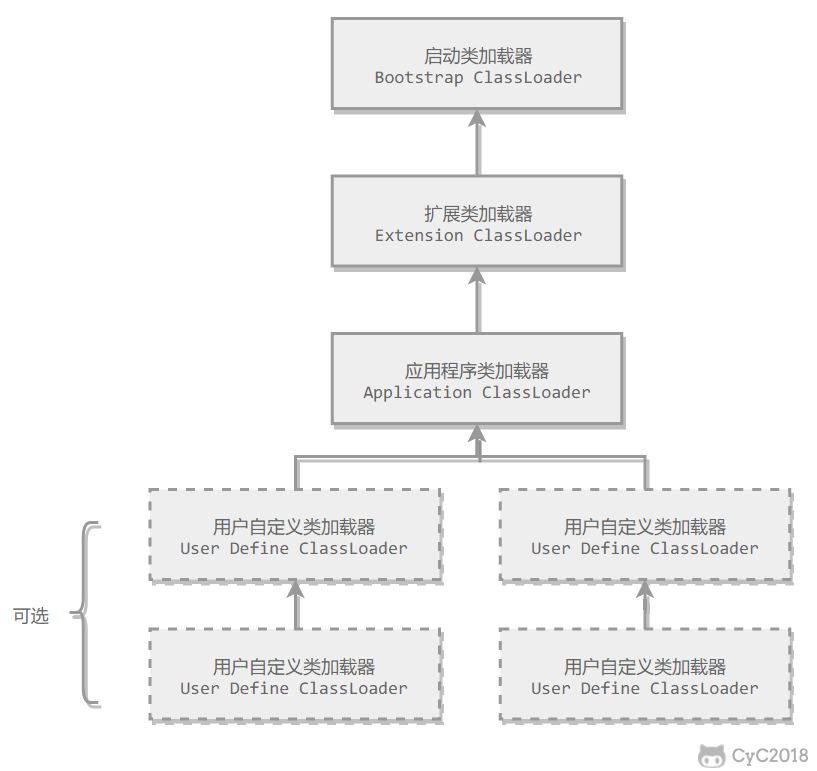
启动类加载器:
负责加载
<JAVA_HOME>\lib目录下 或 -Xbootclasspath参数指定路径 的类库(还必须时JVM可以识别的类库,名字不符的类库即使路径正确也不会加载)。启动类加载器无法被Java程序直接引用,用户编写自定义类加载器时,可将加载请求委派给启动类加载器处理。扩展类加载器:
负责加载
<JAVA_HOME>\lib\ext目录下 或 java.ext.dirs系统变量指定路径 的所有类库。是Java系统类库的扩展机制,可自行添加到ext目录下扩展Java SE功能。应用程序类加载器
加载用户类路径(ClassPath)上的全部类库,如果程序中没有自定义类加载器,一般情况下这个就是默认的类加载器。
自定义类加载器
可自定义拓展,如增加除磁盘位置外的Class文件来源。
各种类加载器之间的层次关系被称为类加载器的 “双亲委派模型”。
双亲委派模型要求除顶层的启动类加载器外,其余的类加载器都要有自己的父类加载器。这里父子关系通过组合关系实现,而非继承关系。
工作流程
一个类加载器首先将类加载请求委派给父加载器完成,每个层次的类加载器都是如此,最终所有的加载请求都会传送到顶层的启动类加载器,只有当父加载器无法完成加载请求时(其搜索范围内没有需要的类),子加载器才会尝试自行加载。
优点
双亲委派让类加载器之间具有优先级的层级关系,使得Java基础类稳定运行,避免类重复加载。
由于最终都是委派给启动类加载器类进行加载,因此Object类在程序的各种类加载器中都能保证是同一个类,而没有双亲委派模型,任由各个类加载器自行加载,我们自行编写一个Object类放到ClassPath中,系统中就会出现多个不同的Object类,导致Java体系的基础无从保证。


